Published inbytearrayDoing range gets on cloud storage for fun and profitThe thing that stands between good and great cloud read performanceNov 28, 2023Nov 28, 2023
Published inbytearrayCorrections in data lakehouse table format comparisonsA live document to serve as a point of reference for corrections for inaccuracies for different comparative studies of Hudi, Delta Lake, or…Apr 20, 20222Apr 20, 20222
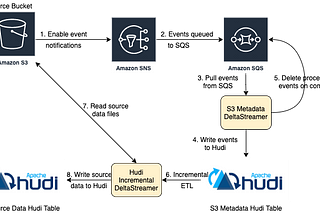
Published inapache-hudi-blogsReliable ingestion from AWS S3 using HudiIn this post we will talk about a new deltastreamer source which reliably and efficiently processes new data files as they arrive in AWS S3Sep 2, 2021Sep 2, 2021
Published inapache-hudi-blogsApache Hudi — The Streaming Data Lake PlatformThis blog is a repost of the original blog hereJul 27, 2021Jul 27, 2021
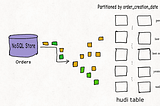
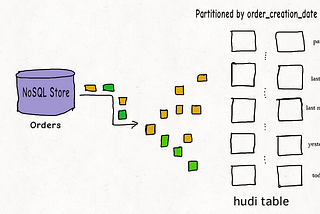
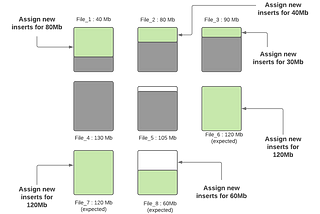
Published inapache-hudi-blogsStreaming Responsibly Into the Data LakeHow Apache Hudi maintains optimum sized filesMar 15, 2021Mar 15, 2021
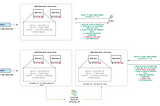
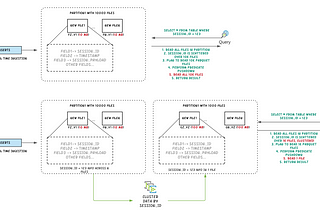
Published inapache-hudi-blogsOptimize Data Lake layout using Clustering in Apache HudiThis blog is a repost of this Hudi blog on medium.Jan 28, 2021Jan 28, 2021
Published inapache-hudi-blogsEmploying the right indexes for fast updates, deletes in Apache HudiThis blog is a repost of this Hudi blog on medium.Dec 19, 2020Dec 19, 2020
Published inbytearrayApache Hudi (Incubating) Support on Apache ZeppelinReposted translation of the original article : https://mp.weixin.qq.com/s/_mNwL5uXSDYyqtLDPx0iDAApr 27, 2020Apr 27, 2020
Embrace the Data Lake ArchitectureOften times, data engineers build data pipelines to extract data from external sources, transform them and enable other parts of the…Jun 8, 2019Jun 8, 2019
Published inbytearraySetting up Hadoop/YARN/Spark/Hive on Mac OSX[Reposted from my blogger]Sep 16, 2018Sep 16, 2018